Introduction
This model is sourced from the Pharmaceutical sector and proves an excellent example of how certain large models, when structured properly, can take advantage of DPL’s various compile time optimizations to give you insightful results at exceedingly manageable runtimes.
Model and Results
The additive model, which you may note is decision-less, represents a sales forecast for Miebedar, a new pharmaceutical drug in development. The model incorporates uncertainties surrounding dosing and usage within various therapeutic areas to come up with a projection of units sold per region. Units are then multiplied by a pricing uncertainty for each region to reach a forecast of Total Miebedar Sales:
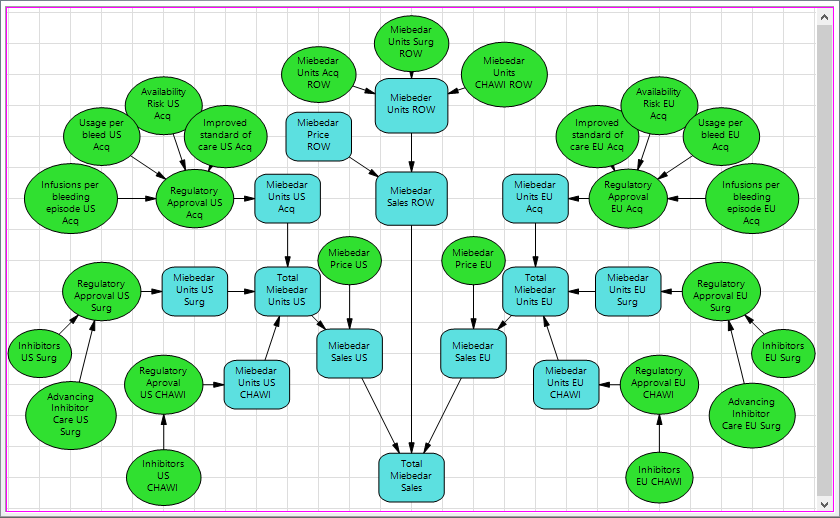
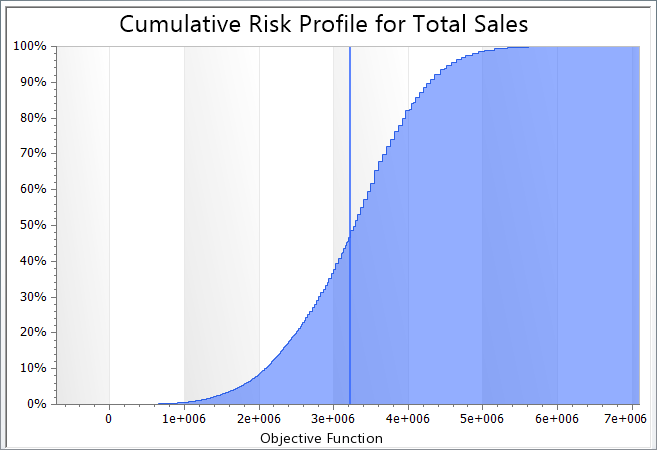
The output of most interest is DPL’s Risk Profile, which illustrates the range of uncertainty for Miebedar’s sales:
MOTM Tip – Promoting Expressions
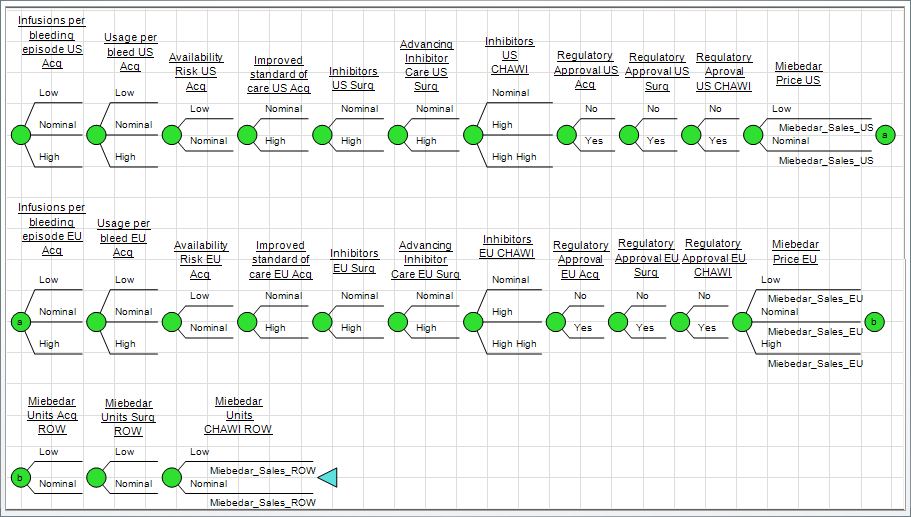
This additive, symmetric forecast model calculates only a single output metric (Total Miebedar Sales), so intuition would have you place this value as the get/pay expression at the end of the decision tree – but doing so would inhibit DPL’s optimizations. In other words, DPL cannot break down the structure of the tree so it’s necessary to visit all 500+ million endpoints to get results.
To remedy this you can “promote expressions”, or break down the get/pay expression into component values (Miebedar Sales US, Miebedar Sales EU, etc.) and move these as far up in the tree as possible. That allows DPL’s optimizations to take the tree apart and get the answer without actually traversing the 500+ million paths.
The Test
I ran the model twice…
(1) No Optimization, a single get/pay value at the end of the tree: runtime was just under 15 hours.
(2) With Optimization, three promoted get/pay values in the tree: runtime was just under 3 seconds.
Now how is that for optimization?